
Your AI just told a customer that your company is “currently led by” an executive who left two years ago. Or it confidently stated that a feature you discontinued in 2023 is “still available.” Nobody flagged it. Nobody caught it. The customer read it, believed it, and made a decision based on it.
That’s not a small error. That’s temporal hallucination — and it’s one of the most underestimated risks in enterprise AI deployment today.
Let’s be honest: most conversations about AI hallucination focus on made-up facts or fabricated citations. But temporal hallucination is different. It’s sneakier. The information was once true. That’s what makes it so dangerous.
Temporal hallucination happens when an AI model presents outdated information as if it’s currently accurate. The model doesn’t “know” time has passed. It mixes timelines, misplaces events, or confidently delivers yesterday’s truth as today’s fact.
Here’s the thing — large language models (LLMs) are trained on data with a fixed cutoff. Once training ends, the model’s internal knowledge freezes. The world keeps moving. The model doesn’t.
So when someone asks, “Who runs Company X?” or “When did COVID-19 start?” — the model doesn’t pause to say, “Wait, let me check if this is still accurate.” It generates what statistically sounds right based on its training data. And sometimes, that data is months or years out of date.
According to research from leading NLP surveys, once an LLM is trained, its internal knowledge remains fixed and doesn’t reflect changes in real-world facts. This temporal misalignment leads to hallucinated content that can appear completely plausible — right up until it causes real damage.
The three most common forms of temporal hallucination you’ll see in production AI systems:
None of these sound like hallucinations. They sound like facts. That’s the problem.
Most AI errors are obvious. A model that writes “the moon is made of cheese” fails immediately. You know something went wrong.
Temporal hallucination doesn’t fail visibly. It passes. It reads well. It’s grammatically correct and contextually coherent. The only thing wrong with it is that it’s no longer true — and neither the user nor the system knows that without external verification.
The business risk is real. In legal and compliance contexts, courts worldwide issued hundreds of decisions in 2025 addressing AI hallucinations in legal filings, with incorrect AI-generated citations wasting court time and exposing firms to liability. In healthcare, hallucination rates in clinical AI applications can reach 43–67% depending on case complexity.
Here’s what most people miss: your users trust AI outputs more when they sound confident. And temporal hallucinations are always confident. The model doesn’t hedge. It doesn’t say, “This might be outdated.” It states it as fact — with full grammatical authority.
For CEOs and CTOs deploying AI in customer-facing roles, this is the scenario that keeps you up at night. Not a system that breaks. A system that works — just with the wrong information.
Understanding why temporal hallucination happens helps you build the right defences.
LLMs learn from massive datasets collected up to a specific date. After that cutoff, training stops. The model is essentially a very sophisticated snapshot of the world as it existed at a point in time. When you deploy that model six months later — or two years later — that gap becomes the source of risk.
There’s another layer to this. Research shows that models are especially prone to hallucination when dealing with information that appears infrequently in training data. Lesser-known regional facts, niche industry data, recent regulatory changes — these are exactly the areas where temporal hallucination strikes hardest, because the training signal was already thin to begin with.
The real question is: what do you do about it?
You don’t need to rebuild your AI stack from scratch. The fixes are architectural, not philosophical. Here’s what actually works.
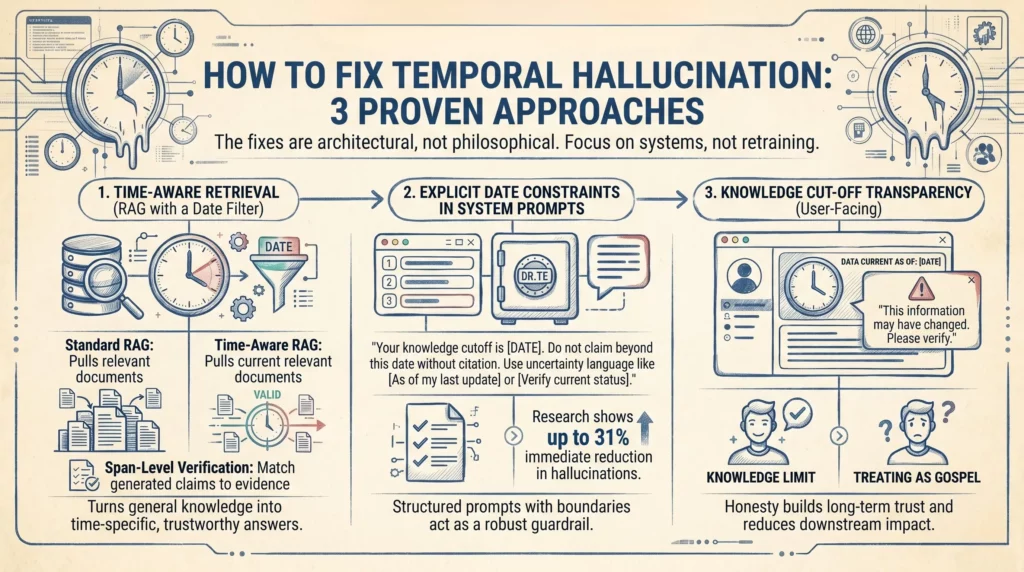
Retrieval-Augmented Generation (RAG) is already one of the strongest tools against hallucination in general. But for temporal hallucination specifically, you need to take it one step further: date-filtered retrieval.
Standard RAG pulls in relevant documents. Time-aware RAG pulls in relevant documents that are current. You add a temporal filter to your retrieval layer — documents older than your defined threshold simply don’t get served to the model.
This is the difference between “here’s everything we know about X” and “here’s everything we know about X that was written in the last 12 months.” For a customer service AI, an internal knowledge assistant, or a compliance tool — this distinction is everything.
One important note: even well-curated retrieval pipelines can still fabricate citations. The most reliable systems now add span-level verification, where each generated claim is matched against retrieved evidence and flagged if unsupported. That’s the extra layer that turns a good RAG system into a trustworthy one.
This one is simpler than it sounds, and it works faster than most technical teams expect.
When you design your system prompt — the instruction set that tells the AI how to behave — you include explicit temporal boundaries. Something like:
“Your knowledge cutoff is [Date]. Do not make claims about events, people, or policies beyond this date without citing a retrieved source. If you are uncertain about whether information is current, say so explicitly.”
Research on AI guardrails shows that structured prompts with explicit constraints can reduce hallucinations by around 31% immediately — with no model retraining required. That’s not a trivial gain. For a deployed enterprise AI, that’s the difference between a reliable tool and a liability.
Combine this with an instruction to use uncertainty language when the model isn’t sure — “as of my last update” or “please verify this is still current” — and you’ve built in a self-disclosure mechanism that significantly reduces the risk of confident, incorrect temporal claims.
The third fix operates at the interface level rather than the model level. And it’s often overlooked because it feels like a UX decision rather than an AI safety one.
When users understand that an AI has a knowledge cutoff, they apply appropriate scepticism. When they don’t, they treat everything as gospel. This isn’t about hiding limitations — it’s about honesty that builds long-term trust.
Best practice: display the model’s knowledge cutoff date clearly in the interface. Add a note when the AI is answering a question that’s likely time-sensitive. For high-stakes outputs — anything involving personnel, pricing, regulation, or recent events — surface a prompt that says: “This information may have changed. Please verify before acting.”
It feels like a small thing. It fundamentally changes how users interact with AI outputs — and it dramatically reduces the downstream impact of any temporal errors that do slip through.
Let’s ground this in real scenarios, because temporal hallucination isn’t an abstract research problem. It shows up in production systems every day.
B2B SaaS customer support: An AI assistant trained on product documentation from early 2023 confidently tells a user that a particular integration is available — an integration that was deprecated eight months ago. The user spends three hours trying to configure something that no longer exists. Support ticket created. Trust eroded.
Healthcare & Life Sciences: A clinical AI references treatment guidelines that have since been updated. The dosage recommendation it cites was revised following new safety data. In this domain, outdated is not just inconvenient — it’s potentially dangerous.
Automotive & Manufacturing: A compliance AI cites a regulatory requirement that was amended last quarter. A procurement decision is made on the basis of a rule that no longer applies exactly as stated.
In every case, the AI did exactly what it was designed to do. It generated a confident, coherent, grammatically correct response. The problem wasn’t that the system failed. The problem was that the system succeeded — with stale data.
Here’s the honest truth about temporal hallucination: you can’t eliminate it entirely. Researchers have formally proven that some level of hallucination is mathematically inevitable in current LLM architectures. But you can contain it. You can engineer around it. And you can build systems where the failure mode is a transparent acknowledgment of uncertainty — not a confident, damaging wrong answer.
The companies that are winning with AI in 2025 and beyond aren’t those deploying the most powerful models. They’re deploying the most governed models — systems wrapped in the right constraints, retrieval layers, and transparency mechanisms that make AI output trustworthy at scale.
At Ai Ranking, we help businesses build AI systems that perform reliably in the real world — not just in demos. Temporal hallucination is one of the ten AI failure patterns we audit for in every enterprise deployment. Because a model that sounds right but isn’t is worse than a model that stays silent.
Ready to assess your AI stack for temporal and other hallucination risks? Let’s talk.
How can you supercharge your business with bespoke solutions and products.
