
If you think your vision-language AI is finally “seeing” your data correctly, you might want to look closer.
We see this mistake all the time. Engineering teams plug a state-of-the-art vision model into their tech stack, assuming it will reliably extract data from charts, read complex handwritten documents, or flag visual defects on an assembly line. For the first few tests, it works flawlessly. High-fives all around.
Then, quietly, the model starts confidently describing objects that don’t exist, misreading critical graphs, and inventing data points out of thin air.
This is multimodal hallucination, and it is a massive, incredibly expensive problem.
Even the best vision-language models in 2026 hallucinate on 25.7% of vision tasks. That is significantly worse than text-only AI. While text hallucinations grab the mainstream headlines, visual errors are quietly bleeding enterprise budgets—contributing heavily to the estimated $67.4 billion in global losses from AI hallucinations in 2024.
Let’s be honest: treating a vision-language model like a standard text LLM is a recipe for failure. What most people miss is that multimodal models don’t just hallucinate facts; they hallucinate physical reality. When an AI hallucinates text, you get a bad summary. When an AI hallucinates vision, you get automated systems rejecting good products, approving fraudulent insurance claims, or feeding bogus financial data into your ERP.
Here is what multimodal hallucination actually means, why it’s fundamentally different (and more dangerous) than regular LLM hallucination, and the exact architectural fixes enterprise teams are using to stop it right now.
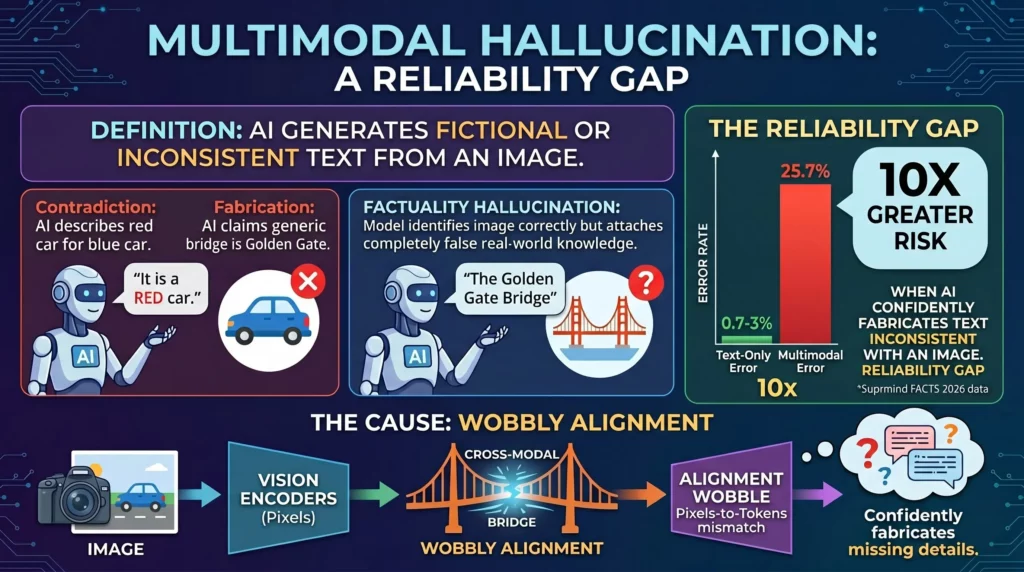
At its core, multimodal hallucination happens when a vision-language model generates text that is entirely inconsistent with the visual input it was given, or when it fabricates visual elements that simply aren’t there.
While text-only models usually stumble over logical reasoning or obscure facts, multimodal models fail at basic observation. These failures generally fall into two distinct buckets:
Faithfulness Hallucination: The model directly contradicts what is physically present in the image. For example, the image shows a blue car, but the AI insists the car is red. It is unfaithful to the visual prompt.
Factuality Hallucination: The model identifies the image correctly but attaches completely false real-world knowledge to it. It sees a picture of a generic bridge but confidently labels it as the Golden Gate Bridge, inventing a geographic fact that the image doesn’t support.
According to 2026 data from the Suprmind FACTS benchmark, multimodal error rates sit at a staggering 25.7%. To put that into perspective, standard text summarization models currently sit between an error rate of just 0.7% and 3%.
Why the massive, 10x gap in reliability? Because interpreting an image and translating it into text requires cross-modal alignment. The model has to bridge two entirely different ways of “thinking”—pixels (vision encoders) and tokens (language models). When that bridge wobbles, the language model fills in the blanks. And because language models are optimized to sound authoritative, it usually fills them in wrong, with absolute certainty.
Not all visual errors are created equal. If you want to fix your system, you need to know exactly how it is breaking. Recent surveys of multimodal models categorize these failures into three distinct types. You are likely experiencing at least one of these in your current stack.
This is the most straightforward, yet frustrating, failure. The model claims an object is in an image when it absolutely isn’t.
The Example: You ask a model to analyze a busy street scene for an autonomous driving dataset. It successfully lists cars, pedestrians, and traffic lights. Then, it confidently adds “bicycles” to the list, even though there isn’t a single bike anywhere in the frame.
Why it happens: AI relies heavily on statistical co-occurrence. Because bikes frequently appear in street scenes in its training data, the model’s language bias overpowers its visual processing. The text brain says, “There should be a bike here,” so it invents one.
The Business Impact: In insurance tech, this looks like an AI assessing drone footage of a roof and hallucinating “hail damage” simply because the prompt mentioned a recent storm.
This is where things get significantly trickier. The model sees the correct object but completely invents its properties, colors, materials, or states.
The Example: The AI correctly identifies a boat in a picture but describes it as a “wooden boat” when the image clearly shows a modern metal hull.
The Catch: According to a recent arXiv study analyzing 4,470 human responses to AI vision, attribute errors are considered “elusive hallucinations.” They are much harder for human reviewers to spot at a rapid glance compared to obvious object errors.
The Business Impact: Imagine using AI to extract data from quarterly financial charts. The model correctly identifies a complex bar graph but entirely fabricates the IRR percentage written above the bars because the text was slightly blurry. It’s a high-risk error wrapped in a highly plausible format.
Here, the model identifies the objects and attributes correctly but fundamentally misunderstands the spatial relationships, actions, or the overarching context of the scene.
The Example: The model describes a “cloudless sky” when there are obvious storm clouds, or it claims a worker is “wearing safety goggles” when the goggles are actually sitting on the workbench behind them.
Why it happens: Visual question answering (VQA) requires deep relational logic. Models often fail here because they treat the image as a bag of disconnected items rather than a cohesive 3D environment. They can spot the worker, and they can spot the goggles, but they fail to understand the spatial relationship between the two.
If vision-language models are supposed to be the next frontier of artificial intelligence, why are they making amateur observational mistakes?
The short answer is architectural misalignment. Think of a multimodal model as two different workers forced to collaborate: a Vision Encoder (the eyes) and a Large Language Model (the brain).
The vision encoder chops an image into patches and turns them into mathematical vectors. The language model then tries to translate those vectors into human words. But when the image is ambiguous, cluttered, or low-resolution, the vision encoder sends weak signals.
When the language model receives weak signals, it doesn’t admit defeat. Instead, it defaults to its training. It falls back on text-based probabilities. If it sees a kitchen counter with blurry blobs, its language bias assumes those blobs are appliances, so it confidently outputs “toaster and coffee maker.”
Worse, poor training data exacerbates the issue. Many foundational models are trained on billions of internet images with noisy, inaccurate, or automated captions. The models are literally trained on hallucinations.
But the real danger is how these models present their wrong answers. A 2025 MIT study, highlighted by RenovateQR, revealed that AI models are actually 34% more likely to use highly confident language when they are hallucinating. This creates a deeply deceptive environment, turning the tool into a confident liar in your tech stack. The model is inherently designed to prioritize answering your prompt over admitting “I cannot clearly see that.”
Furthermore, as you scale these models in enterprise environments, you introduce more complexity. Processing massive 50-page PDF documents with embedded images and charts often leads to context drift hallucinations, where the model simply forgets the visual constraints established on page one by the time it reaches page forty.
We aren’t just talking about a consumer chatbot giving a quirky wrong answer about a dog photo. We are talking about broken core enterprise processes. When multimodal models fail in production, the blast radius is wide.
Healthcare & Life Sciences: Medical image analysis tools fabricating findings on X-rays or misidentifying cell structures in pathology slides. A hallucinated tumor is a catastrophic system failure.
Retail & E-commerce: Automated cataloging systems generating product descriptions that directly contradict the product photos. If the image shows a V-neck sweater and the AI writes “crew neck,” your return rates will skyrocket.
Financial Services & Banking: Document extraction tools misinterpreting visual graphs in competitor prospectuses, skewing investment data fed to analysts.
Manufacturing QA: Vision models inspecting assembly lines that hallucinate “perfect condition” on parts that have glaring visual defects, letting bad inventory ship to customers.
The financial drain is measurable and growing. According to 2026 data from Aboutchromebooks, managing and verifying AI outputs now costs an estimated $14,200 per employee per year in lost productivity. Even more alarming, 47% of enterprise AI users admitted to making business decisions based on hallucinated content in the past 12 months.
Teams fall into a logic trap where the AI sounds perfectly reasonable in its written analysis, but is completely wrong about the visual evidence right in front of it. Because the text is eloquent, humans trust the false visual analysis.
You cannot simply train hallucination out of a foundational AI model. It is an inherent flaw in how they predict tokens. But you can engineer it out of your system. Here are the three architectural guardrails that actually move the needle for enterprise teams.
Retrieval-Augmented Generation (RAG) isn’t just for text databases anymore. Multimodal RAG forces the model to anchor its answers to specific, verified visual evidence retrieved from a trusted database.
Instead of asking the model to simply “describe this document,” you treat the page as a unified text-and-image puzzle. Using region-based understanding frameworks, you force the AI to map every claim it makes back to a specific bounding box on the image. If the model claims a chart shows a “10% drop,” the prompt engineering forces it to output the exact pixel coordinates of where it sees that 10% drop.
If it cannot provide the bounding box coordinates, the output is blocked. According to implementation guides from Morphik, applying proper multimodal RAG and forced visual grounding can reduce visual hallucinations by up to 71%.
You need to build systems that know when they are guessing.
By implementing uncertainty scoring for visual claims, you can categorize outputs into the “obvious vs elusive” framework. Modern APIs allow you to extract the logprobs (logarithmic probabilities) for the tokens the model generates. If the model’s confidence score for a critical visual attribute—like reading a smeared serial number on a manufactured part—drops below 85%, the system should automatically halt.
You don’t just reject the output; you route it to a human-in-the-loop UI. Setting these strict, mathematical escalation thresholds prevents the model from guessing its way through your most critical workflows. Let the AI handle the obvious 80%, and let humans handle the elusive 20%.
Never trust the first output. Build a secondary, adversarial verification loop.
Advanced engineering teams use techniques like Cross-Layer Attention Probing (CLAP) and MetaQA prompt mutations. Essentially, after the main vision model generates a claim about an image, an independent, automated “verifier agent” immediately checks that claim against the original image using a slightly mutated, highly specific prompt.
If the primary model says, “The graph shows revenue trending up to $15M,” the verifier agent isolates that specific span of text and asks the vision API a simple Yes/No question: “Is the line in the graph trending upward, and does it end at the $15M mark?” If the two systems disagree, the output is flagged as a hallucination before the user ever sees it.
You don’t need to rebuild your entire software architecture to fix this problem. You just need a structured, phased rollout. Throwing all these guardrails on at once will tank your latency. Here is the week-by-week implementation roadmap that actually works:
Week 1: Establish Baselines and Prompting. Audit your current multimodal prompts. Introduce visual grounding instructions into your system prompts to force the model to cite its visual sources (e.g., “Always refer to a specific quadrant of the image when making a claim”).
Week 2: Introduce Multimodal RAG. Connect your vision-language models to your trusted visual databases using vector embeddings that support images. Enforce strict citation rules for any data extracted from those images.
Week 3: Implement Confidence Scoring. Add calibration layers to your API calls. Define the exact probability thresholds where a visual task requires human escalation based on your specific industry risk.
Week 4: Deploy Span-Level Verification. For your highest-risk outputs (like financial numbers or medical anomalies), implement the secondary verifier agent to double-check the initial model’s work.
Week 5: Monitor by Type. Stop tracking general “accuracy.” Start tracking specific hallucination rates on your dashboard—monitor object, attribute, and scene-level errors independently. If you don’t know how it’s breaking, you can’t tune the system.
The reality is that multimodal hallucination isn’t a model bug—it’s a systems architecture problem. The fixes aren’t hidden in the weights of the next major AI release; they are in the guardrails you build around your visual-language workflows today.
Even best-in-class models will continue to hallucinate on 1 in 4 vision tasks for the foreseeable future. If you blindly trust the output, an unverified, unguarded vision-language model quickly becomes your most dangerous insider, making critical, confident errors at machine speed.
The fundamental difference between teams that ship reliable multimodal AI and those that end up with failed, unscalable pilots? The successful teams assume hallucination will happen, and they design their entire architecture to catch it.
You might want to rethink how you are approaching your visual data pipelines. Map out exactly where your stack processes text and images together. Those integration points are exactly where multimodal hallucination hides. Start with just one node—add grounding, add secondary verification, and monitor the specific error types—before you cross your fingers and try to scale.
How can you supercharge your business with bespoke solutions and products.
