Here’s something that should make every business leader pause: your AI system might be confidently wrong — and you’d never know by reading the output.
Not wrong in an obvious way. Not a garbled sentence or a broken response. Wrong in the worst possible way — a number that looks real, sounds authoritative, and passes straight through your team’s review process. That’s numerical hallucination in AI, and it’s one of the most underestimated risks in enterprise AI adoption today.
If your business uses AI to generate reports, financial summaries, research insights, or any data-driven content, this isn’t a theoretical problem. It’s a real one, and it’s happening right now in systems across industries.
Let’s break down exactly what it is, why it happens, and — more importantly — how you fix it.
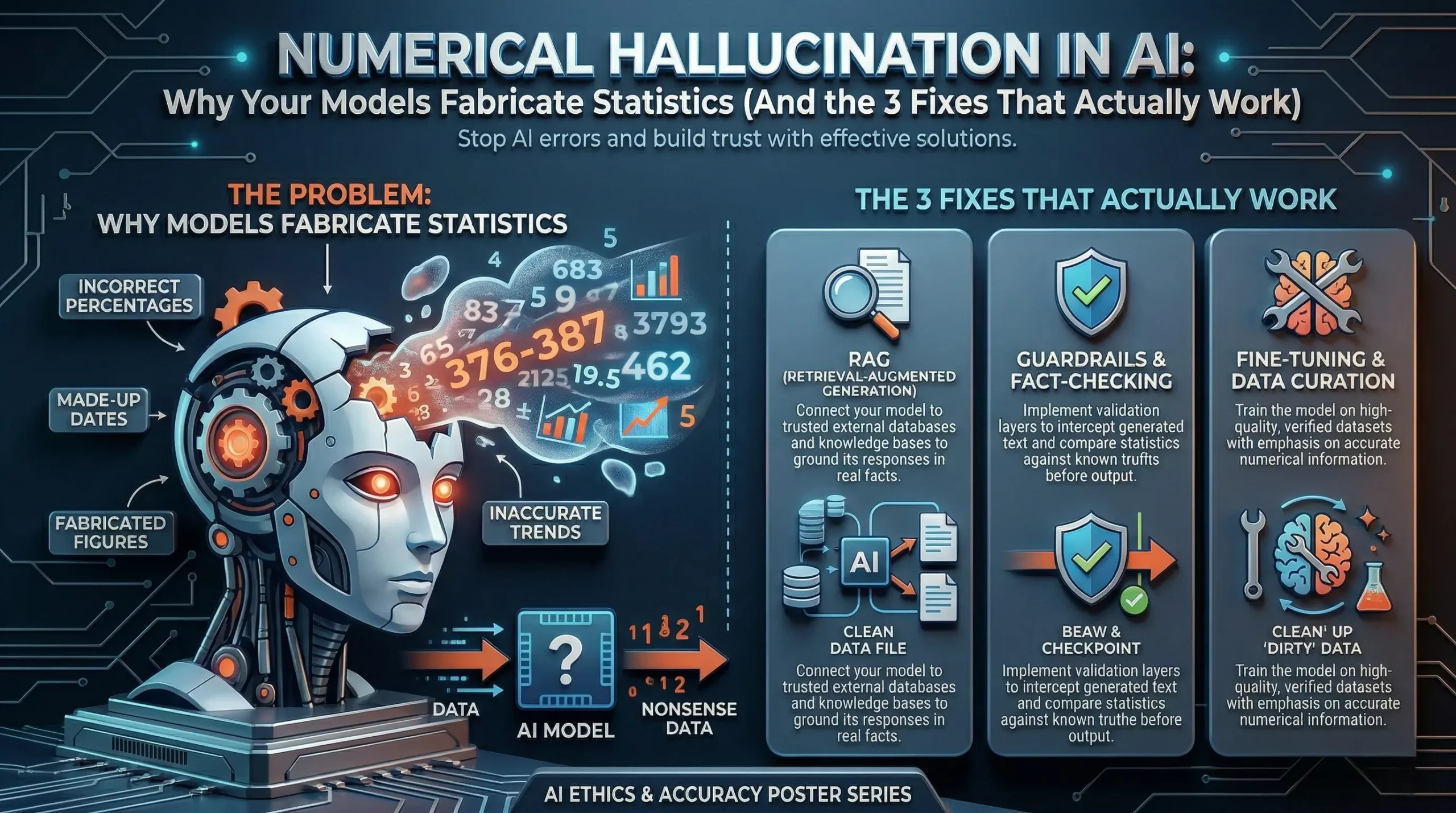
Numerical hallucination in AI is when a language model generates incorrect numbers, statistics, percentages, or calculations — and presents them as fact.
The model doesn’t “know” it’s wrong. That’s what makes this so dangerous. AI language models are trained to predict what text should come next based on patterns. When you ask a model a quantitative question, it generates what a plausible answer looks like — not what the actual answer is.
The result? Things like:
These aren’t typos. They’re confident, fluent, and completely fabricated — and that combination is what makes quantitative AI errors so costly.
This is the part most AI explainers skip, and it’s worth understanding if you’re making decisions about AI deployment.
Language models learn from text. Enormous amounts of it. But text doesn’t always contain verified numerical data. A model trained on web content has seen millions of sentences with numbers — some accurate, many outdated, some just plain wrong. The model doesn’t store a database of facts. It stores patterns of how information is expressed.
So when you ask “What is the global e-commerce market size?”, the model doesn’t look it up. It generates a number that fits the expected shape of that kind of answer. If the training data contained that figure cited as “$4.9 trillion” in some contexts and “$6.3 trillion” in others, the model may generate either — or something in between.
There are a few specific reasons AI models struggle with quantitative accuracy:
No grounded memory. Standard large language models don’t have access to live databases. They’re working from a frozen snapshot of training data.
Numerical interpolation. Models sometimes blend or interpolate between different figures they’ve seen during training, producing numbers that feel statistically plausible but aren’t tied to any real source.
Overconfidence without verification. Unlike a human analyst who would flag uncertainty, an AI model presents all outputs with the same confident tone — whether it’s correct or not.
Outdated training data. If a model’s training data cuts off in 2023, and you’re asking about 2024 market figures, the model will still generate something — it just won’t be grounded in anything real.
This is why statistical errors in AI systems aren’t random flukes. They’re structural. And they require structural fixes.
Let’s be honest — if an AI writes an oddly phrased sentence, someone catches it. But when an AI generates a plausible-looking number in a market analysis or quarterly report, most teams don’t question it.
Here’s what that looks like in practice:
A strategy team uses an AI-generated competitive analysis. The model cites a competitor’s market share as 34%. The real figure is 21%. Pricing decisions, positioning, and resource allocation get shaped around a number that was never real.
Or consider a healthcare organisation using AI to summarise clinical data. An incorrect dosage percentage slips through. The downstream consequences in that kind of environment don’t need spelling out.
Incorrect financial projections from AI models have already influenced board-level discussions in enterprise companies. The damage isn’t always visible immediately — that’s what makes it compound over time.
This is the operational risk that most AI adoption frameworks underestimate. And it’s the reason AI accuracy validation has to be built into deployment, not bolted on after the fact.
The good news is this problem is solvable. Not perfectly, not with a single toggle — but systematically, with the right architecture.
The most direct fix for AI generating false numbers is to stop asking it to recall numbers at all.
When AI models are connected to live tools — calculators, databases, APIs, or retrieval systems — they stop generating numerical answers from memory. Instead, they pull real figures from verified sources and present those.
Think of it like the difference between asking someone to recall a phone number from memory versus handing them a phone book. The output reliability changes completely.
This is what’s often called Retrieval-Augmented Generation (RAG) for structured data — and for any business-critical numerical output, it should be the baseline, not the exception.
If your AI deployment is generating financial data, compliance figures, or statistical summaries without being grounded to a live data source, that’s a structural gap. Not a model limitation — a deployment design gap.
Even when AI models are well-designed, errors can slip through. Structured numeric validation adds a verification layer that catches quantitative inconsistencies before they reach end users.
This works in a few ways:
This kind of AI output validation is particularly important in regulated industries — financial services, healthcare, legal — where a single incorrect figure can trigger compliance issues or erode trust instantly.
The key shift here is moving from treating AI output as final to treating it as a first draft that passes through validation before it matters.
Grounded data retrieval means designing your AI system so that every significant numerical claim has a retrievable, attributable source — not just a generated output.
This goes beyond basic RAG. Grounded retrieval means the AI system cites where a number came from, and that citation is verifiable. If the system can’t find a grounded source for a figure, it says so — rather than filling the gap with a plausible-sounding fabrication.
For enterprise teams, this changes the accountability model for AI-generated content. Instead of “the AI said this,” your team can say “this figure came from [source], retrieved on [date].” That’s the difference between AI as a liability and AI as a trustworthy analytical tool.
Grounded data retrieval is especially important in AI applications for knowledge management, market intelligence, and regulatory reporting — three areas where the cost of an AI accuracy problem is highest.
If you’re a CTO, CDO, or business leader evaluating or scaling AI systems right now, here’s the real question: how does your current AI deployment handle numerical outputs?
If the answer is “the model generates them,” that’s the gap.
The organisations that are getting the most value from AI right now aren’t the ones running the most powerful models. They’re the ones that have built the right guardrails — verification layers, grounded data pipelines, and structured validation — so their AI outputs are trustworthy at scale.
Numerical hallucination in AI isn’t an argument against using AI. It’s an argument for using it correctly.
The difference between an AI system that creates risk and one that creates value is often not the model itself. It’s the architecture around it.
AI language models are not databases. They don’t recall facts — they generate plausible text. For most tasks, that’s good enough. For anything numerical, that distinction is critical.
The fix isn’t to avoid AI for quantitative work. The fix is to build AI systems where numbers are retrieved, not recalled — validated, not assumed — and always traceable to a real source.
If you’re building or scaling AI systems in your organisation and want to get the architecture right from the start, that’s exactly what we help with at Ai Ranking. Because a confident AI that’s confidently wrong is worse than no AI at all.
How can you supercharge your business with bespoke solutions and products.
