
Your AI agents are not the problem. Your data is.
Most organizations investing heavily in AI automation hit the same invisible wall. The tools are purchased, the agents are deployed, and the dashboards look impressive. But the outputs are wrong. Decisions are off. The team loses trust in the system within weeks.
Here is the real reason: poor data quality is quietly undermining everything your AI agents are supposed to do. It is not a technology failure. It is a data failure that was always there, just waiting for an autonomous system to expose it at scale.
This is the twelfth sign in the AI Agent Readiness Series, which examines fifteen critical gaps that prevent organizations from running AI agents reliably. If your AI agents are producing unreliable outputs, inconsistent results, or decisions that nobody trusts, data quality is almost certainly the root cause. Let us get into exactly why, and what you can do about it.
Most executives interpret data quality as a technical concern they delegate to their data teams. That is understandable, but it misses the real business exposure.
For AI agents, data quality is not just about clean spreadsheets or well-labelled databases. It covers every piece of information an agent reads, references, or acts on when executing a task. That means CRM records with inconsistent customer names, ERP entries with missing cost codes, product catalogues with outdated pricing, and patient records with duplicate entries across systems.
AI agents do not verify data before they use it. They cannot pause and say this looks wrong. They process what they are given and produce outputs accordingly. When the input is corrupted, incomplete, or contradictory, the agent delivers garbage outputs at the speed of automation.
The old principle applies perfectly here: garbage in equals garbage out. The difference is that a human analyst might catch an anomaly before it becomes a decision. An AI agent running at scale will not.
Here is what that looks like in practice. An agent managing procurement approvals reads outdated supplier pricing data and commits to orders at rates that are no longer valid. An agent handling patient scheduling pulls from a record that has not been updated since a system migration, and books appointments for inactive patients. An agent producing financial summaries aggregates figures from two databases that use different fiscal calendar definitions.
None of these failures are caused by the AI being wrong. They are caused by the data being wrong. Understanding this distinction is the first step toward fixing it.
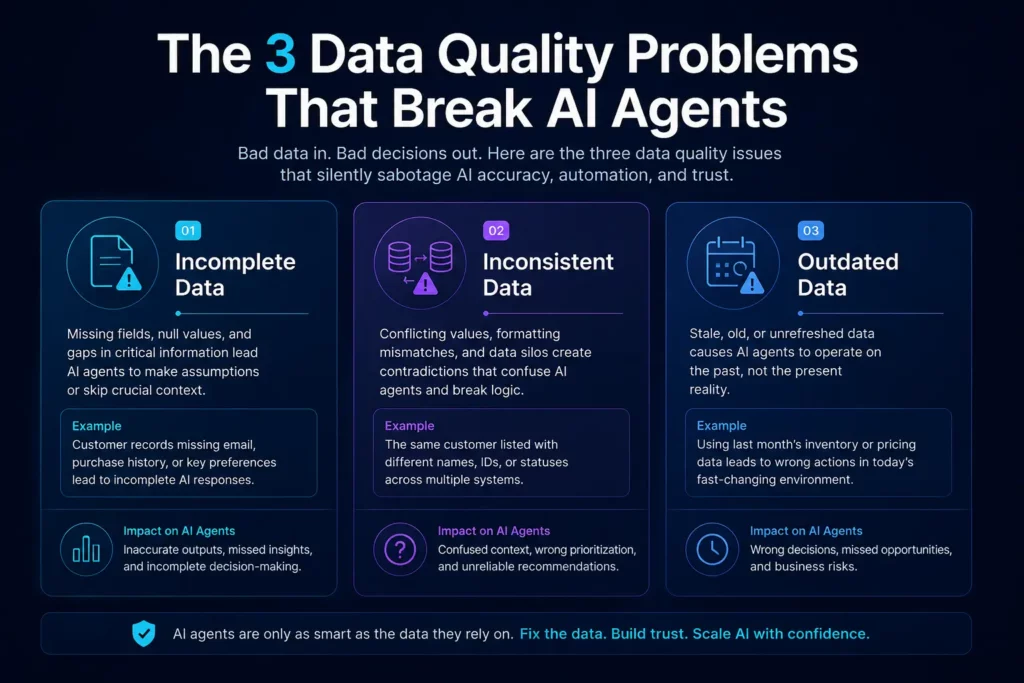
Not all data problems carry equal risk. When it comes to AI agents specifically, three patterns cause the most downstream damage.
Incomplete data means fields that should contain information are empty, null, or populated with placeholder values. For a human reading a report, an empty field is a flag to follow up. For an AI agent, it is often a signal to skip that record, make an assumption, or produce an output that excludes a critical variable.
In healthcare, incomplete patient records can lead an AI agent to generate clinical summaries that miss relevant diagnoses. In finance, incomplete transaction logs can cause automated reconciliation agents to produce reports that regulators will immediately question. The agent does not know what it does not know.
If your organization struggles with fragmented knowledge living across tools and teams, you already have a data completeness problem. Understanding how scattered knowledge silently sabotages AI performance is directly connected to why incomplete data causes agent failures.
Inconsistency is more dangerous than incompleteness because it is harder to detect. Inconsistent data is present but contradictory. The same customer appears with three different company names across CRM, billing, and support systems. The same product has different SKU codes in two warehouses. The same employee has a start date in HR that does not match what is in payroll.
AI agents that draw from multiple data sources will encounter these contradictions and resolve them in ways that are technically logical but contextually wrong. The agent sees two valid records and chooses one. Nobody flags the discrepancy. The output looks clean. The decision is still wrong.
This is closely linked to the challenge of multiple versions of truth across enterprise systems. Organizations that have not resolved that problem at the data architecture level are not ready to run AI agents safely.
An AI agent making decisions based on information that was accurate six months ago is making decisions in the past. Outdated data creates a time-lag between reality and what the agent believes to be true.
This is particularly acute in industries where conditions change quickly. Market data, inventory levels, regulatory requirements, contract terms, and customer preferences all shift. An agent relying on stale records will produce recommendations that are confidently wrong.
The connection between real-time data access and AI agent reliability deserves its own dedicated analysis, and it does. Organizations building AI agents without live data pipelines are setting themselves up for this exact failure mode.
Here is what makes this genuinely dangerous for leadership to understand. Human teams and poor data quality exist in a kind of friction that slows the damage. A sales manager spots that the customer record looks off. A finance analyst questions the number before it goes into the report. Manual verification acts as a natural buffer.
AI agents remove that buffer. When you automate a process that runs on poor data, you do not just replicate the existing error rate. You accelerate it. What was previously one wrong decision per week becomes one hundred wrong decisions per day, all consistent, all automated, and all downstream from the same corrupted source.
Scale is the thing that makes poor data quality existentially risky for AI deployments. Organizations that have not established an approval and review layer before AI-generated outputs reach decision-makers are particularly exposed. Automation without oversight turns a manageable data problem into a systemic one.
The damage compounds further when there are no metrics in place to measure AI performance. If you are not tracking the accuracy of your agent outputs against known baselines, poor data quality will go undetected for months. By the time someone notices, the contamination has spread across multiple systems, reports, and business decisions.
Most data quality frameworks are designed for reporting and compliance. They are not built for the speed and autonomy of AI agent operations. Before you deploy any AI agent in a live business process, you need to run a different kind of assessment.
Start with your primary data sources. For every data asset an agent will access, ask four questions:
Who owns this data and is responsible for keeping it accurate? Organizations without clear AI ownership tend to have the same gap in data ownership. Nobody claims responsibility, so nobody maintains it.
How often is this data validated against a known source of truth? If the answer is quarterly or during audits, that cadence is too slow for autonomous agent operations.
What happens when a record is missing or contradictory? Is there a defined fallback, or does the system just make a choice? AI agents need explicit rules for handling data exceptions.
Is this data sourced from a live system or a static export? Static exports introduce version drift. Agents reading from exports are almost always working with data that is already partially outdated.
The answers to these four questions will tell you more about your AI readiness than any vendor briefing. Organizations that cannot answer them confidently are not in a position to deploy AI agents in production.
Fixing data quality for AI operations is not a one-time cleanse. It is an ongoing architecture decision. Here is where to start.
Establish a single source of truth for every data domain that an AI agent will touch. This does not mean consolidating all data into one system. It means defining which system is authoritative for each data type, and making sure agents only read from that system. The documentation of that architecture matters just as much as the architecture itself. Undocumented workflows and unofficial data sources are how poor quality enters the pipeline quietly.
Build automated data validation into every pipeline that feeds an agent. This means schema checks, completeness checks, and anomaly detection that runs before data is served to the agent. Agents should never receive raw, unvalidated input from operational systems.
Instrument your agents to flag data-related failures explicitly. When an agent encounters a missing field, a value outside expected parameters, or a conflict between two sources, that event should be logged, categorized, and reviewed by a human. This is not just good practice. It is how you build the feedback loop that improves data quality over time.
Assign ownership. Every data domain feeding an AI agent needs a named person or team who is accountable for its accuracy. Without ownership, improvement discussions go nowhere. When something breaks, everyone points elsewhere.
Leadership driving AI adoption has to include leadership driving data ownership. If the CTO understands the data quality imperative but business unit heads are not committed to maintaining their data domains, the technical fixes will degrade quickly.
It is worth stepping back and making the positive case, because data quality conversations often stay stuck in risk and remediation.
When your AI agents operate on accurate, complete, and current data, their outputs become something your organization can actually rely on. Agents can close the loop between action and outcome. They can identify patterns that human analysts would miss. They can escalate anomalies correctly. They can produce recommendations that hold up to scrutiny.
That is the version of AI that most organizations are sold when they begin their journey. The reason they do not reach it is almost always data quality. The technology is capable. The data infrastructure is not ready.
Organizations that do invest in data quality before deployment see compounding returns. Every agent that operates reliably builds organizational confidence. That confidence makes the next deployment easier to approve, easier to scale, and easier to integrate into core business processes.
For CEOs and CTOs, the business case for data quality investment is not abstract. It is the difference between AI that generates demonstrable ROI and AI that generates expensive noise.
This article covers sign twelve of the fifteen signs that your organization is not ready for AI agents. But it does not exist in isolation.
Poor data quality is often the downstream consequence of several other readiness gaps. When knowledge is scattered across teams and tools, data completeness suffers. When documentation does not reflect how work actually happens, the data that powers automated processes is built on false assumptions. When no one owns AI outcomes at the organizational level, data domains go unmaintained because there is no accountability structure.
Addressing poor data quality in isolation, without also examining the systemic gaps that produce it, is a short-term fix. If you have not yet worked through the earlier articles in the series, the ones covering scattered knowledge, documentation gaps, and real-time data access are the most directly relevant to what you have read here.
Also relevant: organizations that have not addressed security models built only for human users are often running agents that access data they should not, which compounds every data quality issue described in this article.
You can also review the original LinkedIn post on poor data quality quietly killing your AI agent strategy for additional context.
Poor data quality is not a problem you discover after deploying AI agents. By that point, the damage is already compounding.
The organizations that succeed with AI at scale are the ones that treat data quality as a foundational requirement, not an afterthought. They assess their data before deployment. They build validation into their pipelines. They assign ownership. They measure accuracy and iterate on it.
The good news is that fixing data quality is entirely within your control. It does not require new technology. It requires commitment, ownership, and a clear process.
If you want to know where your organization stands across all fifteen readiness signs, start working through the AI Agent Readiness Series. Ysquare Technology helps enterprises identify and close these gaps before they become production failures. Reach out to the team on LinkedIn to start the conversation.
How can you supercharge your business with bespoke solutions and products.
