
Your team asks AI for technology recommendations. The response? “React is the best framework for every project.” Your HR department wants remote work guidance. AI’s answer? “Remote work increases productivity in all companies.” Your product manager queries user behavior patterns. The output? “Users always prefer dark mode interfaces.”
One rule. Applied everywhere. No exceptions. No nuance. No context.
This is overgeneralization hallucination—and it’s quietly sabotaging decisions in every department that relies on AI for insights. Unlike factual hallucinations where AI invents statistics, or context drift where AI forgets what you said three messages ago, overgeneralization happens when AI takes something that’s sometimes true and treats it like a universal law.
The catch? These recommendations sound perfectly reasonable. They’re backed by real patterns in the training data. They cite actual trends. And that’s exactly why they’re dangerous—they slip past the BS detector that would catch an obviously wrong answer.
Here’s the core issue: AI learns from patterns. When it sees “remote work” associated with “productivity gains” in thousands of articles, it starts treating that correlation as causation. When 70% of frontend projects in its training data use React, it assumes React is the correct choice—not just a popular one.
The model isn’t lying. It’s pattern-matching without understanding that patterns have boundaries.
Think about how absurd these statements sound when you apply them to real situations:
“Remote work increases productivity” → Tell that to the design team that needs in-person collaboration for rapid prototyping, or the customer support team where timezone misalignment kills response times.
“React is the best framework” → Not if you’re building a simple blog that needs SEO, or a lightweight landing page where Vue’s smaller bundle size matters, or an internal tool where your entire team knows Angular.
“AI-powered customer support improves satisfaction” → Except when customers need empathy for complex issues, or when the chatbot can’t escalate properly, or when your support team’s human touch is actually your competitive advantage.
The pattern AI learned is real. The universal application is fiction.
Overgeneralization doesn’t announce itself. It creeps into everyday decisions:
Development recommendations: AI suggests microservices architecture for every new project—even the simple MVP that would be faster as a monolith.
Security guidance: AI pushes zero-trust frameworks universally—without considering your startup’s resource constraints or risk profile.
Performance optimization: AI recommends caching strategies that work for high-traffic apps but add complexity to low-traffic internal tools.
Hiring advice: AI generates job descriptions requiring “5+ years experience”—copying a pattern from big tech without considering your actual needs.
Each recommendation sounds professional. Each is based on real data. And each ignores the context that makes it wrong for your situation.
Let’s be honest about what’s happening under the hood.
AI models trained on internet data absorb whatever patterns dominate that data—which means majority opinions get treated as universal truths. If 80% of tech blog posts praise remote work, the AI learns “remote work = good” as a hard rule, not “remote work sometimes works for some companies under specific conditions.”
The training process rewards confident pattern recognition. It doesn’t reward saying “it depends.”
When AI encounters a question about work arrangements, it doesn’t think “what’s the context here?” It thinks “what pattern did I see most often in my training data?” And then it generates that pattern with full confidence.
Here’s where it gets messy. AI architecture itself encourages overgeneralizations by spitting out answers with certainty baked in. The model doesn’t say “React might work well here.” It says “React is the recommended framework.” That certainty makes you trust it—which makes you less likely to question edge cases.
Even worse? User feedback reinforces this behavior. When people rate AI responses, they upvote confident answers over nuanced ones. “It depends on your use case” gets lower engagement than “Use approach X.” So the model learns to skip the nuance and just give you the popular answer.
Here’s what actually happens when you ask AI a technical question:
The model doesn’t know whether you’re a 5-person startup or a 5,000-person enterprise. It doesn’t understand that your team’s skill set or your product’s constraints might make the “best practice” completely wrong for you.
It just knows what it saw most often during training.
Just like AI Hallucination: Why Your AI Cites Real Sources That Never Said That showed how AI invents quotes that sound plausible, overgeneralization invents rules that sound authoritative—because they’re based on real patterns, just applied to the wrong situations.
Most companies don’t track “bad advice from AI.” They track the consequences: projects that took longer than expected, architectures that became technical debt, hiring decisions that led to turnover.
One SaaS company asked AI to help design their new analytics feature. The AI recommended a microservices architecture with separate services for data ingestion, processing, and visualization.
Sounds enterprise-grade. Sounds scalable. Sounds like exactly what a serious B2B product should have.
The problem? They had three engineers and needed to ship in two months. Building and maintaining microservices meant implementing service mesh, container orchestration, distributed tracing, and inter-service communication—before writing a single line of actual feature code.
Six months later, they’d spent their entire engineering budget on infrastructure instead of the product. They eventually scrapped it all and rebuilt as a monolith in three weeks.
The AI wasn’t wrong that microservices work for large-scale systems. It was wrong that microservices work for this team, this timeline, this stage of company growth.
A fintech startup used AI to draft their post-pandemic work policy. The AI recommendation: “Full remote work increases productivity and employee satisfaction across all roles.”
The policy went live. Three months later, their design team quit.
Why? Because product design at their company required rapid iteration cycles, whiteboard sessions, and immediate feedback loops that video calls couldn’t replicate. What worked for engineering (async code reviews, focused deep work) failed catastrophically for design.
The AI had learned from thousands of articles praising remote work. It had never learned that different roles have different collaboration needs—or that “increases productivity” is meaningless without specifying “for which roles doing which types of work.”
A startup asked AI to recommend their frontend framework. AI said React—because React dominates the training data. They built their entire product in React.
Two problems:
First, none of their developers had React experience (they were a Python shop). Second, their product was a simple content site that needed SEO—where frameworks like Next.js or even plain HTML would’ve been simpler.
They spent four months learning React, building tooling, and fighting hydration issues—when they could’ve shipped in two weeks with simpler tech their team already knew.
The AI pattern-matched “modern web app” → “React” without asking “what does your team know?” or “what does your product actually need?”
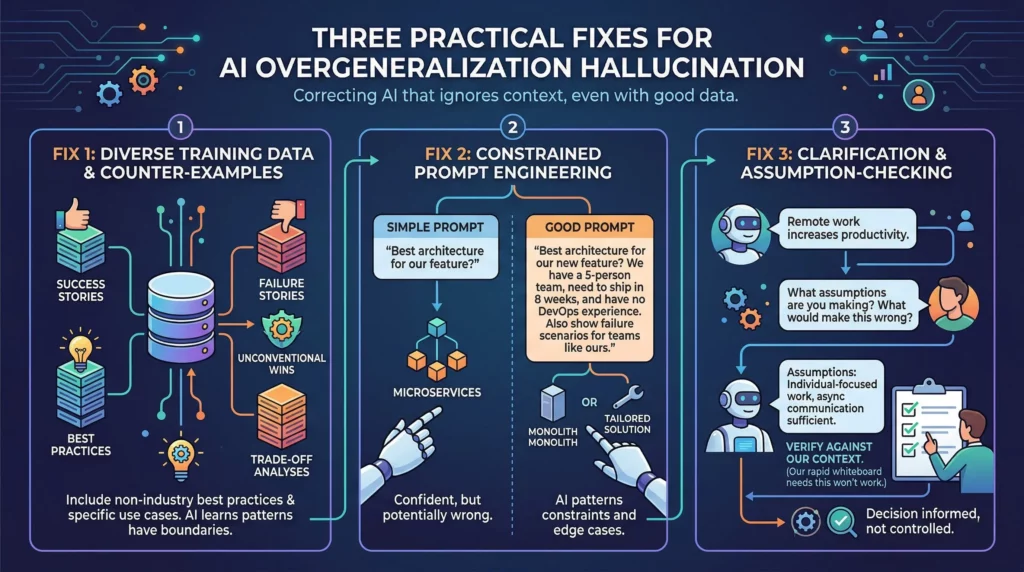
The good news? Overgeneralization is the easiest hallucination type to fix—because the problem isn’t that AI lacks information. It’s that AI ignores context.
When AI models are trained on datasets showing multiple valid approaches across different contexts, they’re less likely to overgeneralize single patterns.
If your custom AI system or fine-tuned model only sees success stories (“React scaled to millions of users!”), it learns React = success universally. If it also sees failure stories (“We switched from React to Vue and cut load time by 60%”), it learns that framework choice depends on context.
This means deliberately including:
Case studies of the same technology succeeding and failing in different contexts—not just the wins.
Examples where conventional wisdom doesn’t apply—like when the “wrong” choice was actually right for specific constraints.
Scenarios that show tradeoffs—acknowledging that every approach has downsides depending on the situation.
For enterprise AI systems, this looks like building training datasets that show your actual use cases—not just industry best practices that may not apply to your business.
The simplest fix? Force AI to consider exceptions before generating recommendations.
Instead of: “What’s the best architecture for our new feature?”
Try: “What’s the best architecture for our new feature? Consider that we’re a 5-person team, need to ship in 8 weeks, and have no DevOps experience. Also show me scenarios where the typical recommendation would fail for teams like ours.”
This prompt engineering works because it forces the model to pattern-match against “small team constraints” and “edge cases” instead of just “best architecture.”
You’re not asking AI to be smarter. You’re asking it to search a different part of its training data—the part that includes nuance.
Users can combat AI overconfidence by explicitly requesting uncertainty expressions and assumption statements before accepting recommendations.
Here’s the pattern:
Step 1: Get the initial recommendation
Step 2: Ask: “What assumptions are you making about our situation? What would make this recommendation wrong?”
Step 3: Verify those assumptions against your actual context
This works because it forces AI to make its pattern-matching explicit. When AI says “Remote work increases productivity,” you can ask “What are you assuming about team structure, communication needs, and work types?”
The answer might be: “I’m assuming most work is individual-focused deep work, teams are geographically distributed anyway, and async communication is sufficient.”
Now you can evaluate whether those assumptions match reality.
Similar to The “Smart Intern” Problem: Why Your AI Ignores Instructions, the issue isn’t that AI can’t understand context—it’s that AI needs explicit prompts to surface context before making recommendations.
Here’s what most companies get wrong: they treat AI recommendations as research, when they’re actually pattern repetition.
The question “What’s the best framework/architecture/process/tool?” is designed to produce overgeneralized answers. It’s asking AI to rank patterns by frequency, not by fit.
Better questions:
“What are three different approaches to X, and what are the tradeoffs of each?”
“When would approach X fail? Give me specific scenarios.”
“What assumptions does the standard advice make? How would recommendations change if those assumptions don’t hold?”
These questions force AI to engage with nuance instead of just ranking popularity.
The most effective fix is context injection—making your specific situation so explicit that AI can’t pattern-match around it.
This looks like:
Starting every AI conversation with “We’re a 10-person startup in fintech with X constraints”—before asking for advice.
Creating internal documentation that AI tools can reference before making recommendations.
Building custom prompts that include your team’s actual skill sets, timelines, and constraints upfront.
When you make context unavoidable, overgeneralization becomes much harder.
AI is excellent at showing you what patterns exist in its training data. It’s terrible at knowing which pattern applies to your specific situation.
That means:
Use AI to surface options you hadn’t considered—it’s great at breadth.
Use AI to explain tradeoffs and common approaches—it knows the landscape.
Use humans to evaluate which option fits your context—only you know your constraints.
Never blindly implement AI recommendations without asking “is this actually true for us?”
The pattern AI learned might be valid. The universal application definitely isn’t.
Overgeneralization hallucination happens when AI mistakes frequency for truth—when “this is common” becomes “this is always correct.”
It’s the most insidious hallucination type because the underlying pattern is real. Remote work does increase productivity for many companies. React is a robust framework. Microservices do scale well. But “many” isn’t “all,” and “can work” isn’t “will work for you.”
The fix isn’t waiting for AI to develop better judgment. The fix is building systems that force context into every recommendation:
Diverse training data that includes counter-examples and failure modes.
Prompts that explicitly request edge cases and alternative scenarios.
Clarification questions that surface hidden assumptions before you commit.
Human evaluation of whether the pattern actually applies to your situation.
If you’re using AI to guide technology decisions, product strategy, or team processes, overgeneralization is already in your systems. The question isn’t whether it’s happening—it’s whether you’re catching it before it cascades into expensive mistakes.
Need help designing AI workflows that preserve context and avoid overgeneralization? Ai Ranking specializes in building AI implementations that balance pattern recognition with business-specific constraints—no universal recommendations, no ignored edge cases, just context-aware guidance that actually fits your situation.
How can you supercharge your business with bespoke solutions and products.
