
You told the AI to answer in one sentence. It gave you five paragraphs.
You said “Python code only, no explanation.” You got code — and three paragraphs of commentary underneath it.
You set a tone rule, a formatting constraint, a hard output limit. The model read all of it, processed all of it, and then went ahead and did whatever it felt like.
That’s instruction misalignment hallucination. And it’s one of the most quietly expensive reliability failures running through enterprise AI deployments right now — not because it’s rare, but because most teams don’t know they have it. They assume the AI understood the instructions. It did. That’s the uncomfortable part. Understanding the rule and following the rule are two completely different things when you’re an LLM.
Here’s what gets missed: this isn’t a comprehension problem. It’s a priority problem. The model read your instruction. It just didn’t weight it correctly against everything else competing for its attention at the moment of generation. In production AI workflows, that distinction changes everything about where you go looking for the fix.
Most discussions about AI hallucination get stuck on the obvious stuff — the model inventing a citation that doesn’t exist, making up a statistic, confidently stating something that’s factually wrong. Those are real and well-documented. But instruction misalignment hallucination is a different category of failure, and it doesn’t get nearly the attention it deserves.
The simplest way to define it: the model generates an output that contradicts, ignores, or partially overrides the explicit instructions, formatting rules, tone requirements, or constraints you gave it. The information might be perfectly accurate. The reasoning might be sound. But the model departed from the rules of the task itself — and it did so without flagging the departure, without hesitation, and with complete confidence.
You’ve almost certainly seen this. You ask for a one-sentence answer and get a 400-word essay. You specify formal tone with no contractions and the output reads like a casual blog post. You define explicit output structure in your system prompt and the model produces a response that technically addresses the question but ignores the structure entirely. Each example feels like a minor inconvenience in a demo environment. In production, where AI outputs feed automated pipelines, trigger downstream processes, or appear directly in front of customers, an ignored formatting constraint can break a parser, flag a compliance review, or generate content that your legal team is going to have questions about.
The scale of this problem is larger than most people expect. The AGENTIF benchmark, published in late 2025, tested leading language models across 707 instructions drawn from real-world agentic scenarios. Even the best-performing model perfectly followed fewer than 30% of the instructions tested. Violation counts ranged from 660 to 1,330 per evaluation set. These aren’t edge cases from adversarial prompts. These are normal instructions, in normal workflows, failing at rates that would be unacceptable in any other production system.
If you want to fix instruction misalignment, you need to understand what’s actually happening when a model processes your prompt — because it’s not reading the way you’d read it.
When a model receives a prompt, it doesn’t move linearly through your instructions, committing each rule to memory before acting on it. It processes the entire input as a weighted probability space. Every token influences the output, but not equally. System-level instructions compete with user messages. User messages compete with retrieved context. Retrieved context competes with the model’s training priors. And the model’s fundamental goal at generation time is to produce the most plausible-sounding continuation of the full input — not the most rule-compliant one.
Researchers call this attention dilution. In long context windows, constraints buried in the middle of a prompt receive significantly less model attention than instructions placed at the start or end. A formatting rule mentioned once, 2,000 tokens into your system prompt, is fighting hard to stay relevant by the time the model starts generating. It often loses that fight.
There’s a second layer to this that’s more structural. Research published in early 2025 confirmed that LLMs have strong inherent biases toward certain constraint types — and those biases hold regardless of how much priority you try to assign the competing instruction. A model trained on millions of verbose, explanatory responses has learned at a statistical level that verbosity is what “correct” looks like. Your one-sentence instruction is asking it to override a deeply embedded training pattern. The model isn’t being difficult. It’s being consistent with everything it was trained on, which just happens to conflict with what you need.
The third factor is what IFEval research identified as instruction hierarchy failure — the model’s inability to reliably distinguish between a system-level directive and a user-level message. When those two conflict, models frequently default to the user message, even when the system prompt was explicitly designed to take precedence. This isn’t a behavior you can override with a cleverly worded prompt. It’s an architectural constraint in how current LLMs process layered instructions.
This is also why the “always” trap in AI language behavior is so tightly connected to instruction misalignment — the same training dynamics that make models overgeneralize and ignore nuance also make them prioritize satisfying-sounding responses over technically compliant ones.
Here’s where this gets expensive in ways that don’t show up anywhere obvious.
Most organizations measure AI reliability through a single lens: output accuracy. Does the answer contain the right information? Instruction compliance is almost never a tracked metric. And that blind spot is costing real money in ways that are very easy to misattribute.
Picture a content pipeline where the model is supposed to return structured JSON for downstream processing. An instruction misalignment event — say, the model decides to add a conversational preamble before the JSON block — doesn’t produce wrong information. It produces a parsing failure. The pipeline breaks. Someone investigates. A workaround gets patched in. Three weeks later it happens again with a slightly different prompt structure. The cycle repeats, and nobody calls it a hallucination because the content was accurate. It just wasn’t in the format that was asked for.
Or think about a customer service AI with a defined tone constraint — “never use first-person language, maintain formal address at all times.” An instruction misalignment event produces a warm, colloquial response. The customer is perfectly happy. The compliance team isn’t — because the interaction gets logged, reviewed, and flagged as off-policy. Now there’s a documentation trail showing your AI consistently violating its own operating guidelines. In regulated industries, that trail matters.
The aggregate cost is substantial. Forrester’s research put per-employee AI hallucination mitigation costs at roughly $14,200 per year. A significant chunk of that is instruction-compliance-related rework — the kind teams have stopped calling hallucination because the outputs didn’t look wrong on the surface. They just didn’t look like what was asked for.
This also compounds directly with context drift across multi-step AI workflows — as models lose track of original constraints across longer interactions, instruction misalignment doesn’t stay isolated. It builds.
Format violations are the most visible version of this problem. The model returns Markdown when you asked for plain text. It adds a full explanation when you asked for code only. It writes five items when you asked for three. These feel minor in testing. In automated pipelines, they’re disruptive.
Tone and style drift is subtler, and considerably more expensive in brand-facing contexts. You specify formal voice — the output reads casual. You ask for neutral, objective language — the output has a persuasive edge. In regulated industries, this moves quickly from a style problem to a compliance problem, and the two are not the same conversation.
Constraint creep is something different again. The model technically addresses what you asked, but expands the scope beyond what you defined. You asked for a 100-word summary. You get the 100-word summary plus “key takeaways” and a “next steps” section nobody requested. Each addition feels like the model being helpful. Collectively, they represent the model consistently deciding that your output boundaries don’t quite apply to it.
Procedural violations are the most serious in agentic contexts. You’ve defined a clear rule: “If the user asks about pricing, direct them to the sales team — do not provide numbers.” The model provides numbers anyway, because the training pattern for “pricing question” strongly associates with “respond with figures.” In an autonomous agent workflow, that’s not a tone misstep. It’s a policy violation with commercial and potentially legal consequences.
This is exactly the dynamic the smart intern problem describes — a model that’s capable enough to understand what you’re asking, and confident enough to override it when its own training pattern suggests a different answer. The more capable the model, the more frequently this shows up.
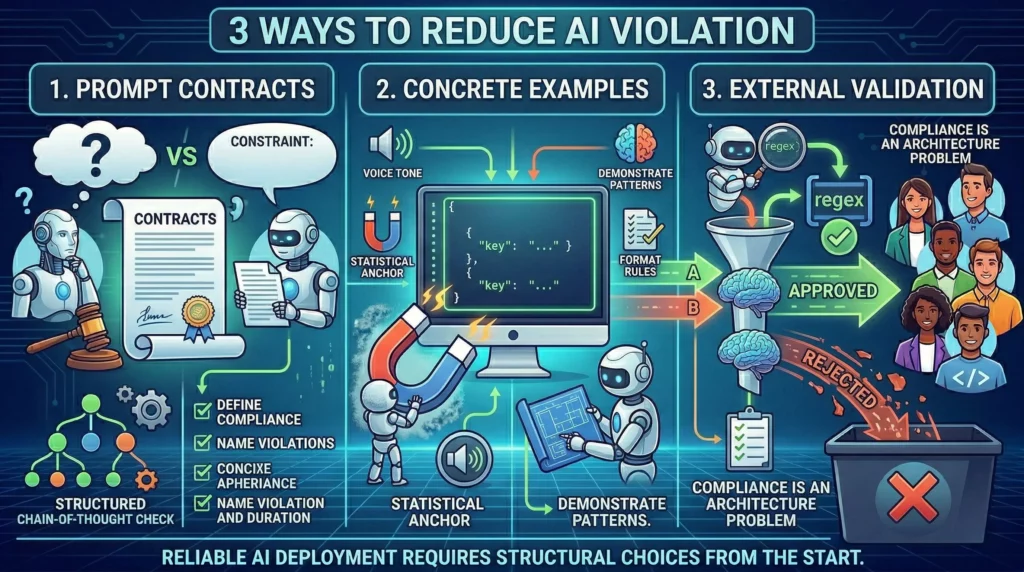
There’s no single fix. But there are structural choices that dramatically shrink the gap between what you instructed and what the model produces.
Write system prompts as contracts, not suggestions. Most system prompts are written as preferences. “Please be concise” is a preference. “Responses must not exceed 80 words. Any response exceeding this word count is non-compliant” — that’s a constraint. The difference matters because models weight explicit, unambiguous directives more heavily than vague style guidance. Define what compliance looks like. Define what non-compliance looks like. Name the specific violations you want to prevent. Structured chain-of-thought constraint checks have been shown to reduce instruction violation rates by up to 20% — not by being more creative with language, but by being more precise about what’s required.
Use concrete output examples, not abstract descriptions. Abstract instructions fail more often than demonstrated ones. Showing the model a compliant output — “here is what a correct response looks like” — gives it a statistical anchor to pull toward. Instead of fighting against training priors with words, you’re demonstrating the desired pattern until it becomes the most probable continuation. This is particularly effective for format constraints, where showing the model exactly what correct JSON structure, correct length, or correct voice looks like consistently outperforms telling it what those things should be.
Build output validation outside the model. Don’t rely on the model to self-comply. The model’s job is to generate. Compliance enforcement should be a system responsibility — a separate validation layer that checks outputs against defined rules before they reach any downstream process or end user. This can be as lightweight as a regex check for format violations, or as thorough as a secondary model tasked with auditing the primary model’s constraint adherence. The principle is the same either way: compliance is not a prompt problem. It’s an architecture problem.
This is the core argument behind the first 60 minutes of AI deployment shaping long-term reliability — the validation architecture you embed from the start determines whether instruction misalignment compounds silently or gets caught at the edge.
Instruction misalignment hallucination sits alongside other failure types that together define what enterprise AI reliability actually looks like in practice.
When a model invents sources it never read, that’s fabricated sources hallucination — a factual grounding failure. When it states incorrect information with confidence, that’s factual hallucination — a knowledge accuracy failure. When it reasons through valid premises to wrong conclusions, that’s logical hallucination — a reasoning integrity failure.
Instruction misalignment is the compliance failure. The output might be factually accurate. The reasoning might hold. But the model departed from the rules governing how it was supposed to behave — and it did so invisibly, without flagging the departure, presenting the non-compliant output with the same confidence it would bring to a fully compliant one.
What makes this particularly difficult to catch is that instruction violations often survive human review. A content reviewer checks for accuracy. They check for tone. They rarely sit down with the original system prompt open in one window and the output in another, checking constraint by constraint. The misalignment slips through. The pipeline keeps running. The gap between what you thought you built and what’s actually operating in production quietly widens.
Let’s be honest about what that means: most enterprises don’t know their instruction compliance rate. They’ve never measured it. And in 2026, with AI agents running deeper into production workflows, that’s the question worth asking before any other.
Your AI is probably not as compliant as you think it is.
That’s not an indictment of the technology — it’s a structural reality of how large language models process and weight instructions. The model read your system prompt. It may have read it carefully. But it also weighed that prompt against its training priors, its context window, and the user message — and in that competition, specific constraints frequently come last.
A better prompt helps, but only so far. The real fix is a better system — one that treats output validation as a structural requirement, writes constraints with the precision of contracts, and measures compliance with the same discipline it applies to accuracy. Instruction misalignment is fixable. But only once you stop treating it as a prompt engineering quirk and start treating it as the production reliability problem it actually is.
YSquare Technology helps enterprises build production-grade AI systems with built-in reliability architecture. If instruction compliance is a live issue in your stack, we’d be glad to help.
How can you supercharge your business with bespoke solutions and products.
