
Your AI just handed you a beautifully structured recommendation — clear reasoning, numbered steps, confident tone.
There’s just one problem: the conclusion is completely wrong.
That’s logical hallucination. And it’s arguably the most dangerous AI failure showing up in enterprise deployments right now — because it doesn’t look like a failure at all.
Unlike a chatbot that makes up a citation or fabricates a source you can Google, logical hallucination hides inside the reasoning itself. The steps feel coherent. The language sounds authoritative. But somewhere in the middle of that chain, a flawed assumption crept in — and the model kept going like nothing happened.
In 2026, as AI agents move from pilots into production workflows, this is the one keeping CTOs up at night.
Most people picture AI hallucination as a model inventing things out of thin air. A fake statistic. A non-existent court case. A product feature that never existed. That’s factual hallucination, and it gets a lot of attention.
Logical hallucination is different. The facts can be perfectly real. What breaks down is the reasoning that connects them.
Here’s the classic example: “All mammals live on land. Whales are mammals. Therefore, whales live on land.” Both premises exist in the training data. The logical structure looks valid. The conclusion is demonstrably false.
Now imagine that happening inside your AI-powered financial analysis tool. Your automated medical triage system. Your customer recommendation engine. The model isn’t inventing things — it’s reasoning. Just badly.
Researchers now categorize this as reasoning-driven hallucination: where models generate conclusions that are logically structured but factually wrong — not because they’re missing knowledge, but because their multi-step inference is flawed. According to emergent research on reasoning-driven hallucination, this can happen at every step of a chain-of-thought — through fabricated intermediate claims, context mismatches, or entirely invented logical sub-chains.
Here’s what most people miss: it’s harder to catch than outright fabrication, because everything looks right on the surface. That’s what makes it dangerous.
Here’s a finding that genuinely shook the AI industry in 2025.
OpenAI’s o3 — a model designed specifically to reason step-by-step through complex tasks — hallucinated 33% of the time on personal knowledge questions. Its successor, o4-mini, hit 48%. That’s nearly three times the rate of the older o1 model, which came in at 16%.
Read that again. The more sophisticated the reasoning, the worse the hallucination rate on factual recall.
Why does this happen? Because reasoning models fill gaps differently. When a standard model doesn’t know something, it often just gets the fact wrong. When a reasoning model doesn’t know something, it builds an argument around the gap — constructing a plausible-sounding logical bridge between what it knows and what it needs to conclude.
MIT research from January 2025 added something even more alarming. AI models are 34% more likely to use phrases like “definitely,” “certainly,” and “without doubt” when generating incorrect information than when generating correct information. The wronger the model is, the more certain it sounds.
For enterprise teams using reasoning-capable AI on strategic decisions, that’s a serious problem. You’re not just getting a wrong answer. You’re getting a wrong answer dressed in a suit, walking confidently into your boardroom.
Most teams catch the obvious hallucination failures. The fake citation spotted before filing. The product feature that doesn’t exist. Those get fixed.
Logical hallucination damage is quieter. And it compounds.
Think about what happens when an AI analytics tool draws a false causal conclusion: “Traffic increased after the redesign, so the redesign caused it.” Post hoc reasoning like that quietly drives investment into the wrong initiatives, warps product decisions, and produces strategy calls that confidently miss the real variable. Nobody flags it, because it sounds exactly like something a smart analyst would say.
The numbers behind this are hard to ignore. According to Forrester Research, each enterprise employee now costs companies roughly $14,200 per year in hallucination-related verification and mitigation efforts — and that figure doesn’t account for the decisions that slipped through unverified. Microsoft’s 2025 data puts the average knowledge worker at 4.3 hours per week spent fact-checking AI outputs.
Deloitte found that 47% of enterprise AI users made at least one major business decision based on hallucinated content in 2024. Logical hallucinations are disproportionately represented in that number — precisely because they’re the hardest to spot during review.
The global financial toll hit $67.4 billion in 2024. And most organizations still have no structured process for measuring what reasoning errors specifically cost them. The failures are quiet. The damage accrues silently.
If you haven’t started thinking about how context drift compounds these reasoning errors across multi-step AI workflows, that’s probably the next conversation worth having.
The reason it evades standard review comes down to something very human: cognitive bias.
When we see structured reasoning — “Step 1… Step 2… Therefore…” — we shortcut the verification. The structure itself signals validity. We’re trained from early on to trust logical form. An argument that looks like a syllogism gets far less scrutiny than a bare claim.
AI reasoning models haven’t consciously figured this out. But statistically, they’ve learned that structured outputs receive more trust and less pushback. The training process — as OpenAI acknowledged in their 2025 research — inadvertently rewards confident guessing over calibrated uncertainty.
There’s also a compounding effect worth knowing about. Researchers have identified what they call “chain disloyalty”: once a logical error gets introduced early in a reasoning chain, the model reinforces rather than corrects it through subsequent steps. Self-reflection mechanisms can actually propagate the error, because the model is optimizing for internal consistency — not external accuracy.
By the time the output reaches an end user, the flawed logic has been triple-validated by the model’s own internal process. It reads as airtight. That’s the catch.
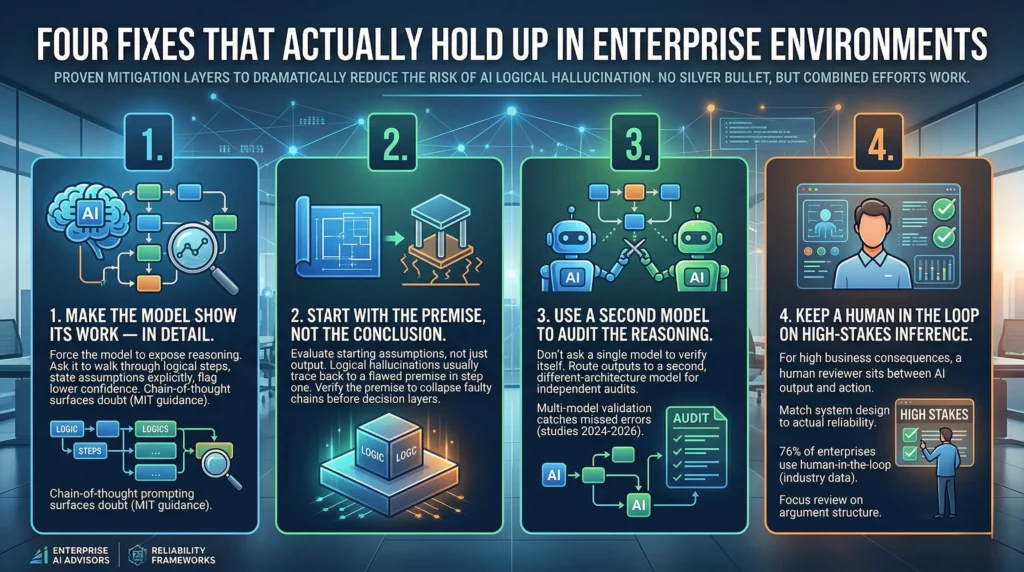
There’s no silver bullet here. But there are proven mitigation layers that, combined, dramatically reduce the risk.
1. Make the model show its work — in detail. Before you evaluate any output, engineer your prompts to force the model to expose its reasoning. Ask it to walk through each logical step, state its assumptions explicitly, and flag where its confidence is lower. Chain-of-thought prompting, when designed to surface doubt rather than just structure, gives your review team something real to interrogate. MIT’s guidance on this approach has shown it exposes logical gaps that would otherwise stay buried in fluent prose.
2. Start with the premise, not the conclusion. Train your review process to evaluate the starting assumptions — not just the output. Logical hallucinations almost always trace back to a flawed or incorrect premise in step one. Verify the premise, and the faulty chain collapses before it reaches your decision layer. Most review processes skip this entirely.
3. Use a second model to audit the reasoning. Don’t ask a single model to verify its own logic. It will almost always confirm itself. Instead, route complex logical outputs to a second model with a different architecture and ask it to audit the steps independently. Multi-model validation consistently catches errors that single-model approaches miss — this has been confirmed across multiple studies from 2024 through 2026.
4. Keep a human in the loop on high-stakes inference. For decisions with real business consequences, a human reviewer needs to sit between the AI’s logical output and the action taken. This isn’t distrust — it’s designing systems that match the actual reliability of the tools you’re using. Right now, 76% of enterprises run human-in-the-loop processes specifically to catch hallucinations before deployment, per industry data. For logical hallucination specifically, that review needs to focus on the argument structure — not just the facts cited.
Let’s be honest: logical hallucination isn’t a problem that better models will simply eliminate.
OpenAI confirmed in 2025 that hallucinations persist because standard training objectives reward confident guessing over acknowledging uncertainty. A 2025 mathematical proof went further — hallucinations cannot be fully eliminated under current LLM architectures. They’re not bugs. They’re inherent to how these systems generate language.
That reframes the whole question. The real question isn’t “which AI doesn’t hallucinate?” Every AI hallucinates. The real question is: what system do you have in place to catch logical errors before they reach a business decision?
This is why the first 60 minutes of AI deployment set the tone for your long-term ROI — the validation frameworks you build in from the start determine whether reasoning errors compound over time or get caught early.
For enterprises serious about AI reliability, the path forward isn’t waiting for models to improve. It’s building reasoning validation into your AI architecture the same way you’d build QA into any critical system — as a structural requirement, not an afterthought you bolt on later.
Logical hallucination is the hallucination type that sounds most like truth. It doesn’t invent facts from nothing — it builds confident, structured arguments on flawed foundations.
In 2026, with AI reasoning models being deployed deeper into enterprise workflows, the risk is growing faster than most organizations are prepared for. The fix isn’t to trust the output less. It’s to build systems that verify the reasoning, not just the result.
If you want to understand the full landscape of AI hallucination types affecting enterprise deployments — from factual errors in AI-generated content to the logical reasoning failures covered here — understanding the difference between confident logic and correct logic is where it starts.
How can you supercharge your business with bespoke solutions and products.
