Tech fails — sometimes unexpectedly, sometimes embarrassingly, sometimes in the middle of your biggest launch. But here’s the part most teams overlook: when a company handles a failure with honesty, speed, and genuine care, customers often trust them more afterward than before anything broke. That moment — where frustration turns into loyalty — is the heart of the Service Recovery Paradox, and it’s quickly becoming one of the most underrated strengths in modern tech

Google’s own research makes it clear: customers don’t expect perfection — they expect responsibility.
Studies consistently show 70% of customers return when an issue is resolved, and 95% return when the fix is fast and respectful.
Huge platforms like Spotify, Cloudflare, AWS, and Azure face outages all the time — nobody is immune.
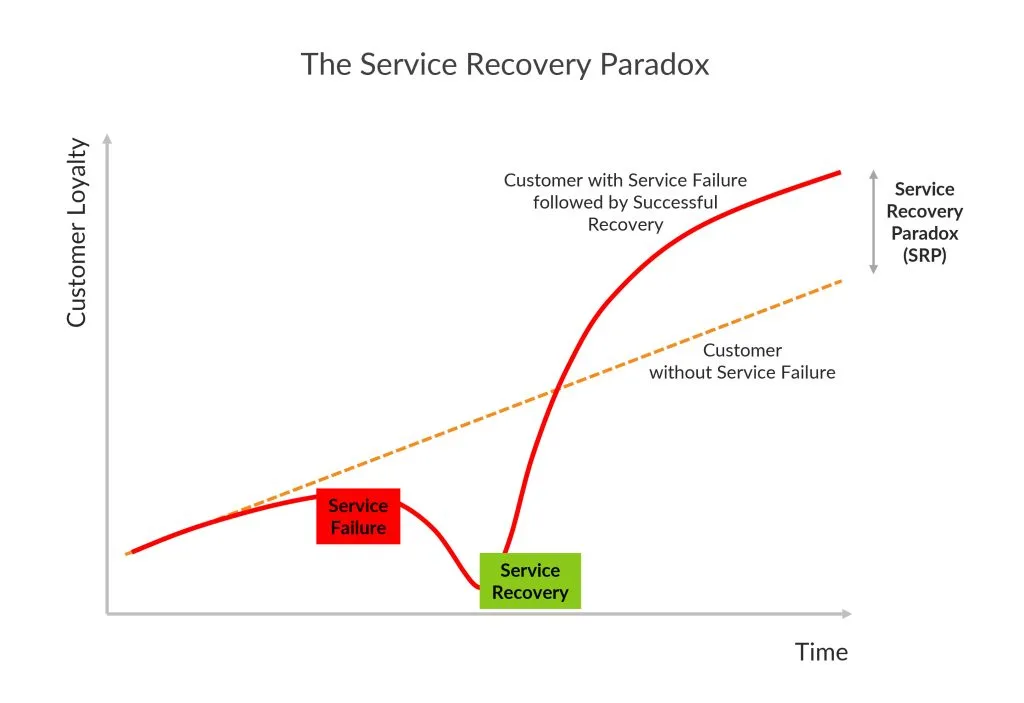
When handled the right way, a failure can actually increase trust and customer loyalty.
Most companies still treat recovery as an afterthought, even though it should be part of the product experience.
In today’s always-online world, recovery is becoming more important than the failure itself.
When Taylor Swift dropped her surprise album, millions of fans jumped into Spotify at the exact same moment. The app froze. Screens got stuck. Logins looped. Everything went sideways in seconds. It looked like a disaster waiting to happen. But Spotify didn’t hide. They communicated clearly, updated regularly, and fixed things fast. Instead of anger, fans felt reassured. Some even praised Spotify for responding so quickly during chaos. That’s exactly what the Service Recovery Paradox looks like in real life — the idea that sometimes the way you recover matters more than the fact that something broke.

Tech failures usually happen in three places: inside the app, within the cloud systems running underneath, or in the analytics that help teams understand what’s going on. And here’s what separates great companies from the rest: they guide users through that moment with calmness and clarity. A friendly human message instead of a confusing error code. Saving progress automatically so users don’t lose everything. Redirecting traffic to backup servers without making noise. Or simply sending a transparent update after the fix. These small gestures transform a moment of panic into a moment of relief — and over time, that relief becomes loyalty.
Most teams fail at recovery because they treat it like a “support problem.” But the best companies treat recovery as part of the product experience itself. They proactively ask: “How might this break?” “What will the user feel in that moment?” “How do we support them before frustration takes over?” This shift changes everything. Recovery becomes intentional instead of reactive. Users feel acknowledged instead of ignored. And every incident becomes a chance to build trust rather than lose it.
Every tech failure tells two stories, and only one of them really matters. The first story — what went wrong — is usually easy for people to forgive. Systems crash, servers overload, unexpected bugs slip through. Users get it. They’ve seen the internet break before. What they remember, and what they judge you by, is the second story: how your team showed up when things weren’t going well. If you respond with honesty instead of silence, empathy instead of excuses, and quick action instead of panic, the entire experience shifts. A moment that could’ve damaged trust becomes one that quietly strengthens it. That’s the real heart of the Service Recovery Paradox. The companies who understand this aren’t afraid of failure — they expect it, they prepare for it, and when it happens, they treat it as a chance to show customers who they really are. One thoughtful recovery at a time, they turn breakdowns into proof of reliability.


How can you supercharge your business with bespoke solutions and products.

