
Here’s something most AI users don’t catch until it’s too late: your AI assistant isn’t just capable of making up facts. It also makes up rules.
We’re talking about AI policy constraint hallucination — a specific failure mode where a large language model (LLM) confidently tells you it “can’t” do something, citing a restriction that simply doesn’t exist. You’ve probably seen it. You ask a perfectly reasonable question, and the AI fires back with something like:
“I’m not allowed to answer that due to OpenAI policy 14.2.”
Except there is no “policy 14.2.” The model invented it on the spot.
This isn’t a small quirk. In enterprise settings, this kind of hallucination erodes user trust, creates compliance confusion, and makes AI systems feel unreliable. Let’s break down exactly what’s happening, why it happens, and — most importantly — what you can do about it.
Policy constraint hallucination is when an AI model invents restrictions, rules, or policies that do not actually exist in its guidelines, system prompt, or operational framework.
It’s one of the lesser-discussed — but more damaging — types of AI hallucination. Most people focus on factual hallucination (the AI making up a fake citation or a nonexistent statistic). That’s a problem too. But at least when a model fabricates a fact, it’s trying to help you. When it fabricates a constraint, it’s actively refusing to help you — based on nothing real.
Here are a few examples of how this plays out in real interactions:
The model isn’t lying in a conscious way. It’s doing what LLMs do: predicting what the next most plausible output should be. And sometimes, the “most plausible” response — given what it’s seen during training — is a refusal dressed up in official-sounding language.
Here’s the thing — understanding why AI models hallucinate constraints gives you real power to prevent them.
Research shows that next-token training objectives and common leaderboards reward confident outputs over calibrated uncertainty — so models learn to respond with authority even when they shouldn’t. That same dynamic applies to refusals. If the model has seen thousands of instances of AI systems politely declining requests using policy language, it learns to associate that pattern with “safe” responses.
The result? When a model is uncertain or uncomfortable with a query, it reaches for what it knows: refusal framing. It doesn’t check whether the cited policy actually exists. It just outputs the most statistically probable next token.
When an AI system is deployed with a vague or incomplete system prompt, the model has to fill in the blanks. Research shows that AI agents hallucinate when business rules are expressed only in natural language prompts — because the agent sees instructions as context, not hard boundaries. If you tell a model to “be careful with sensitive topics” without specifying what that means, it starts making judgment calls. And those judgment calls often come out as invented constraints.
A lot of enterprise AI deployments involve fine-tuning models for safety and alignment. That’s a good thing. But overcalibrated safety training can teach a model to refuse broadly rather than thoughtfully. The model learns to pattern-match on words or topics it associates with “restricted” — even when the actual request is perfectly acceptable.
Let’s be honest: this isn’t just a training problem. Recent studies suggest that hallucinations may not be mere bugs, but signatures of how these machines “think” — and that the capacity to generate divergent or fabricated information is tied to the model’s operational mechanics and its inherent limits in perfectly mapping the vast space of language and knowledge. In other words, some level of hallucination — including policy hallucination — is baked into how LLMs function at a fundamental level.
You might be thinking: “If the AI says no when it shouldn’t, I’ll just try again.” Fair. But the problem runs deeper than a single failed query.
For enterprise teams, policy hallucination creates real operational drag. If your customer-facing AI chatbot tells users it “can’t help with billing queries due to compliance restrictions” — when no such restriction exists — you’ve just created a support escalation that shouldn’t exist, plus a confused and frustrated customer.
For developers and prompt engineers, it introduces a trust gap. If you can’t tell whether an AI’s refusal is based on a real constraint or a fabricated one, you can’t debug it effectively. Industry estimates suggest AI hallucinations cost businesses billions in losses globally in 2025 — and much of that comes from failed automations, misplaced trust, and broken workflows.
For regulated industries — healthcare, finance, legal — a model that invents compliance language can actually create legal exposure. If an AI tells a user something is “not allowed due to regulatory policy” when it isn’t, that misinformation can have real downstream consequences.
Under the EU AI Act, which entered into force in August 2024, organizations deploying AI systems in high-risk contexts face penalties up to €35 million or 7% of global annual turnover for violations — including failures around transparency and accuracy. A model that fabricates regulatory constraints is a liability risk, not just a user experience problem.
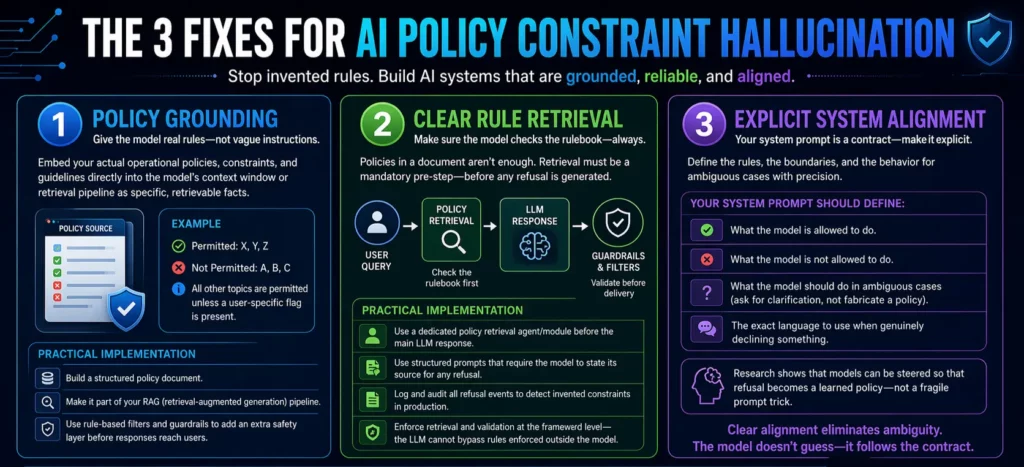
The image that likely brought you here breaks it down simply: policy grounding, clear rule retrieval, and explicit system alignment. Let’s go deeper on each one.
The most effective way to stop a model from inventing rules is to give it real ones — in explicit, structured form.
Policy grounding means embedding your actual operational policies, constraints, and guidelines directly into the model’s context window or retrieval pipeline. Not as vague instructions, but as specific, retrievable facts. Instead of saying “be conservative with legal topics,” you write out: “This system is permitted to discuss X, Y, Z. It is not permitted to discuss A, B, C. All other topics are permitted unless a user-specific flag is present.”
When the model has access to a clear, grounded source of policy truth, it doesn’t need to improvise. The invented constraint has no room to exist because the real constraint is already there.
A practical implementation: build a structured policy document, make it part of your RAG (retrieval-augmented generation) pipeline, and configure the model to consult it before generating any refusal. Even with retrieval and good prompting, rule-based filters and guardrails act as an additional layer that checks the model’s output and steps in if something looks off — acting as an automated safety net before responses reach the end user.
Policy grounding sets up the library. Clear rule retrieval makes sure the model actually uses it.
Here’s the catch: just having your policies in a document doesn’t mean the model will consult them reliably. You need a retrieval mechanism that’s triggered before the model generates a refusal — not after. Think of it as a “check the rulebook first” step built into your AI architecture.
The core insight is to use framework-level enforcement to validate calls before execution — because the LLM cannot bypass rules enforced at the framework level. This principle applies equally to constraint handling. If you build policy retrieval as a mandatory pre-step in your AI pipeline, the model can’t skip it and revert to hallucinated constraints.
Practically, this looks like:
The last point is particularly important. If you can’t see when your model is generating fabricated refusals, you can’t fix them.
This is the foundational layer — and the one most teams underinvest in.
Explicit system alignment means your system prompt is not a vague preamble. It’s a precise contract between you and the model. It states clearly:
Anthropic’s research demonstrates how internal concept vectors can be steered so that models learn when not to answer — turning refusal into a learned policy rather than a fragile prompt trick. That’s the goal: refusals that are grounded in real, steerable, auditable policies — not spontaneous confabulations.
When your system prompt handles these cases explicitly, you eliminate the ambiguity that gives policy hallucination room to breathe. The model doesn’t need to guess. It has clear instructions, and it follows them.
Let’s say you’re deploying an AI assistant for a healthcare SaaS platform. Your users are clinical coordinators, and the AI helps with scheduling and documentation queries.
Without explicit system alignment, your model might respond to a query about prescription details with: “I’m unable to provide medical prescriptions due to HIPAA regulations and platform policy.” That’s a fabricated constraint — your platform never said that, and the user wasn’t asking for a prescription, just documentation guidance.
With the three fixes in place:
The result: fewer false refusals, better user trust, and a much cleaner audit trail for compliance.
Policy constraint hallucination is a symptom of a broader challenge in AI deployment. Most teams focus on making their AI capable. Far fewer focus on making it honest about its limits.
The real question is: can you trust your AI to tell you the truth — not just about the world, but about itself? Can it accurately report what it can and can’t do, based on real constraints rather than invented ones?
That kind of trustworthy AI doesn’t happen by accident. It’s built through deliberate system design: grounded policies, intelligent retrieval, and alignment that’s explicit enough to hold up under real-world pressure.
At Ai Ranking, this is exactly the kind of AI deployment challenge we help businesses navigate. If your AI is generating refusals you didn’t authorize, or citing policies that don’t exist, it’s not just a prompt problem — it’s an architecture problem. And it’s fixable.
If you’re scaling AI in your business and want systems that are reliable, transparent, and aligned with your actual policies — let’s talk. Ai Ranking helps enterprise teams design and deploy AI architectures that perform in the real world, not just in demos.
How can you supercharge your business with bespoke solutions and products.
